
OpenAI员工爆料称,OpenAI已跨过‘递归自我改进’临界点,o4、o5已经能自动化AI研发,越来越多OpenAI员工开始暗示他们已在内部开发了ASI。有传言称,OpenAI已研发出GPT-5,但考虑到模型虽能力强,运营成本太高,用GPT-5蒸馏出GPT-4o、o1、o3这类模型才更具性价比,所以选择了‘雪藏’。
种种迹象表明,最近OpenAI似乎发生了什么大事。
AI研究员Gwern Branwen发布了一篇关于OpenAI o3、o4、o5的文章。
根据他的说法,OpenAI已经跨越了临界点,达到了‘递归自我改进’的门槛——o4或o5能自动化AI研发,完成剩下的工作!

文章要点如下——
– OpenAI可能选择将其‘o1-pro’模型保密,利用其计算资源来训练o3这类更高级的模型,类似于Anthorpic的策略
– OpenAI可能相信他们已经在AI发展方面取得了突破,正在走向ASI之路
– 目标是开发一种运行效率高的超人AI,类似于AlphaGo/Zero所实现的目标
– 推理时搜索最初可以提高性能,但最终会达到极限
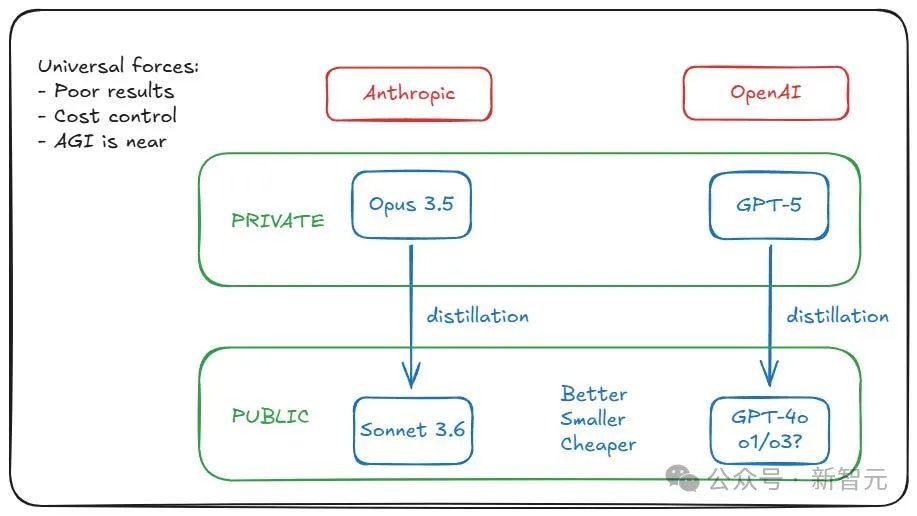
甚至还出现了这样一种传言:OpenAI和Anthropic已经训练出了GPT-5级别的模型,但都选择了‘雪藏’。
原因在于,模型虽能力强,但运营成本太高,用GPT-5蒸馏出GPT-4o、o1、o3这类模型,才更具性价比。
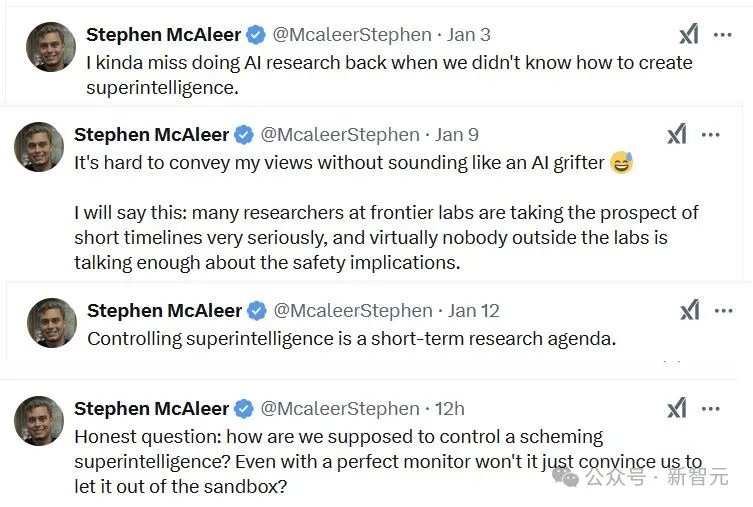
甚至,OpenAI安全研究员Stephen McAleer最近两周的推文,看起来简直跟短篇科幻小说一样——
我有点怀念过去做AI研究的时候,那时我们还不知道如何创造超级智能。
在前沿实验室,许多研究人员都非常认真地对待AI短时间的影响,而实验室之外几乎没有人充分讨论其安全影响。
而现在控制超级智能已经是迫在眉睫的研究事项了。
我们该如何控制诡计多端的超级智能?即使拥有完美的监视器,难道它不会说服我们将其从沙箱中释放出来吗?
总之,越来越多OpenAI员工,都开始暗示他们已经在内部开发了ASI。
这是真的吗?还是CEO奥特曼‘谜语人’的风格被底下员工学会了?
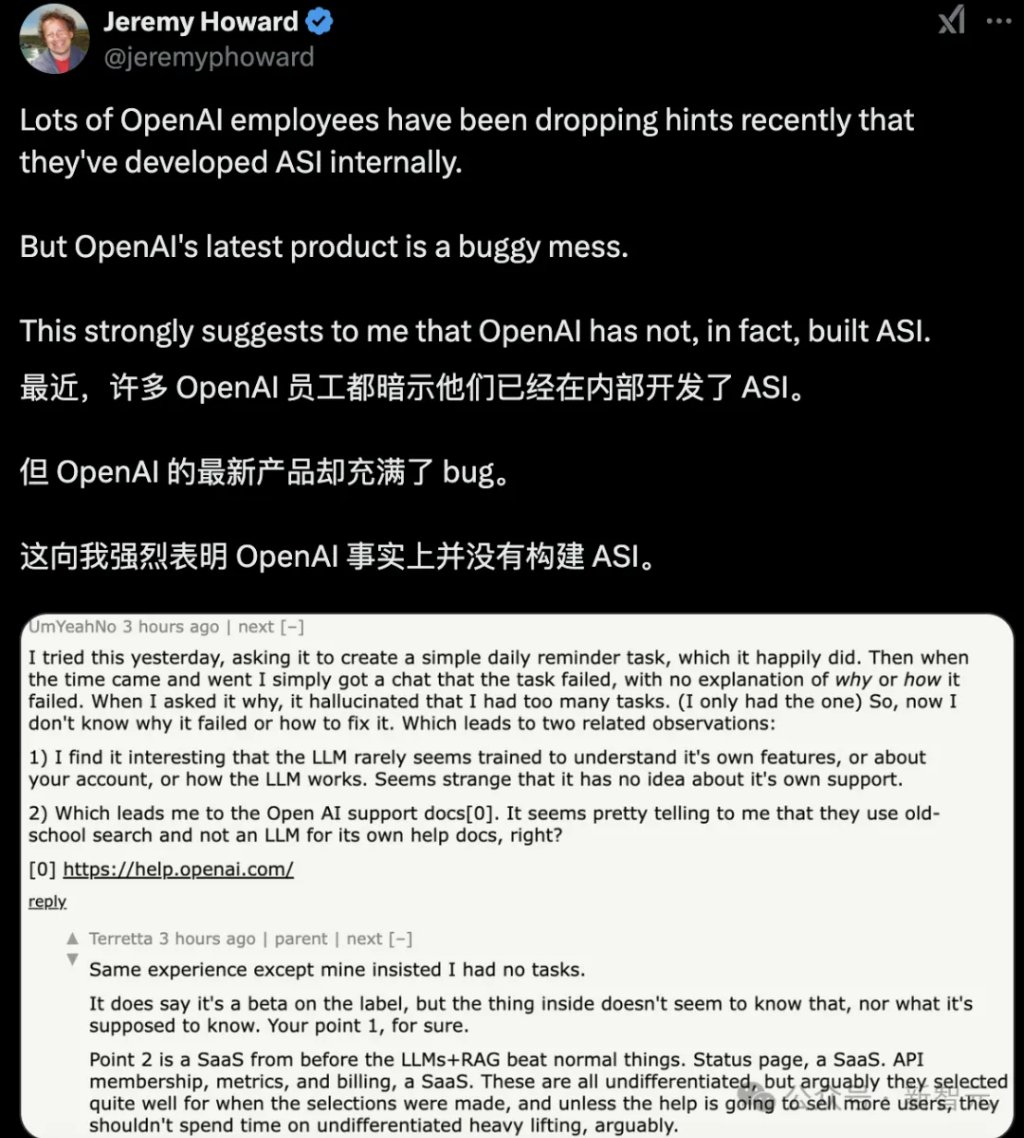
很多人觉得,这是OpenAI惯常的一种炒作手段。


但让人有点害怕的是,有些一两年前离开的人,其实表达过担忧。
莫非,我们真的已处于ASI的边缘?

超级智能(superintelligence)的‘潘多拉魔盒’,真的被打开了?
OpenAI:‘遥遥领先’
OpenAI的o1和o3模型,开启了新的扩展范式:在运行时对模型推理投入更多计算资源,可以稳定地提高模型性能。
如下面所示,o1的AIME准确率,随着测试时计算资源的对数增加而呈恒定增长。
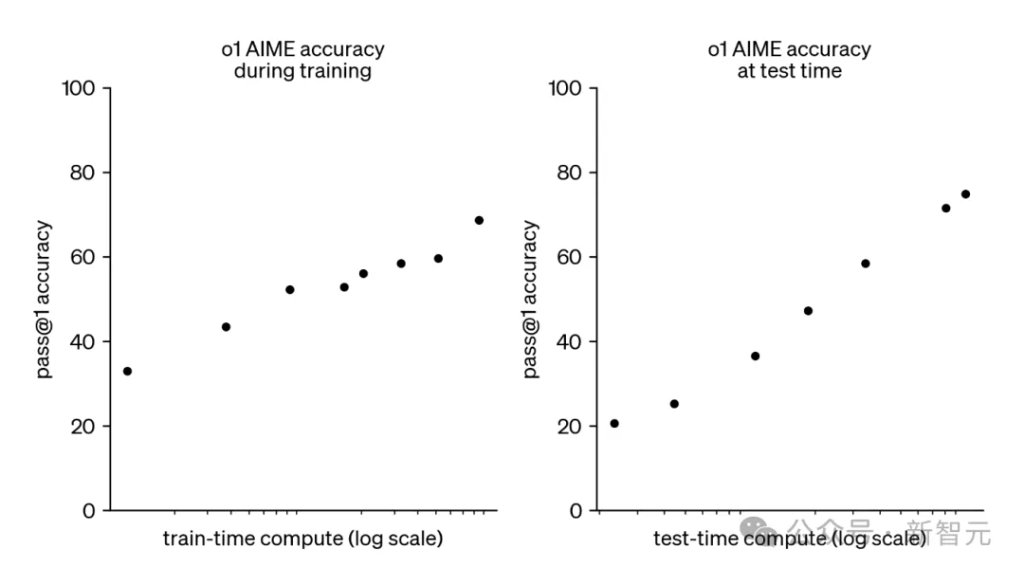
OpenAI的o3模型延续了这一趋势,创造了破纪录的表现,具体成绩如下:
- 在Codeforces上得分2727,使其成为全球第175名最优秀的竞技编程者;
- 在FrontierMath上得分25%,该平台的‘每个问题都需要数学家几个小时的工作’;
- 在GPQA上得分88%,其中70%的分数代表博士级别的科学知识;
- 在ARC-AGI上得分88%,而在困难的视觉推理问题上,平均Mechanical Turk人工任务工人的得分为75%。
根据OpenAI的说法,o系列模型的性能提升主要来自于增加思维链(Chain-of-Thought,CoT)的长度(以及其他技术,如思维树),并通过强化学习改进思维链(CoT)过程。
目前,运行o3在最大性能下非常昂贵,单个ARC-AGI任务的成本约为300美元,但推理成本正以每年约10倍的速度下降!
Epoch AI的一项最新分析指出,前沿实验室在模型训练和推理上的花费可能相似。
因此,除非接近推理扩展的硬性限制,否则前沿实验室将继续大量投入资源优化模型推理,并且成本将继续下降。
就一般情况而言,推理扩展范式预计可能会持续下去,并且将是AGI安全性的一个关键考虑因素。
AI安全性影响
那么推理扩展范式对AI安全性的影响是什么呢?简而言之,AI安全研究人员Ryan Kidd博士认为:
- AGI时间表大体不变,但可能会提前一年。
- 对于前沿模型的部署,可能会减少其过度部署的影响,因为它们的部署成本将比预期高出约1000倍,这将减少来自高速或集体超级智能的近期风险。
- 思维链(CoT)的监督可能更有用,前提是禁止非语言的CoT,这对AI安全性有利。
- 更小的、运行成本更高的模型更容易被盗用,但除非非常富有,否则很难进行操作,这减少了单边主义诅咒的风险。
- 扩展可解释性更容易还是更难;尚不确定。
- 模型可能会更多地接受强化学习(RL),但这将主要是‘基于过程’的,因此可能更安全,前提是禁止非语言的CoT。
- 出口管制可能需要调整,以应对专用推理硬件。





